【杂记】rCore学习摘要-SaZiKK
这是刚开始学习rCore-tutorial-book时的随笔杂记,记录了我的一些思考和学习过程。
rcore学习笔记
教程的环境变量设置似乎有问题,qemu环境变量修改后正常:
1
export PATH="/home/sazikk/qemu-7.0.0/build:$PATH"
2024.2.25
wsl宕机,报错:
1
2
3
占位程序接收到错误数据。
Error code: Wsl/Service/0x800706f7
Press any key to continue...
原因:使用过代理
解决方案:
管理员身份启动cmd/powershell , 运行
1
netsh winsock reset
重启电脑后启动wsl
参考:win10/win11下启动wsl/wsl2出现“占位程序接收到错误数据“启动失败的解决办法
2024.3.3 开始第一章实践
gdb调试qemu无法到达断点0x80200000
原因:修改文件位置导致环境变量失效,启动了错误版本的qemu
解决方案:重设环境变量
必须保证以qemu-7.0.0启动调试,或者去github上自己编译适合更高版本的rustsbi.bin
2024.3.5
qemu启动系统内核流程
首先编译得到内核可执行文件
1
cargo build --release
然后丢弃元数据得到内核镜像
1
rust-objcopy --strip-all <可执行文件> -O binary <内核镜像>
最后启动qemu,加载内核
1
2
3
4
5
qemu-system-riscv64 \
-machine virt \ #设置虚拟机名称为virt
-nographic \ #无图形界面
-bios <bootloader地址> \ #she'zhi
-device loader,file=<内核镜像地址>,addr=0x80200000
如果要启动GDB,在最后加上-s -S,可以使 Qemu 监听本地 TCP 端口 1234 等待 GDB 客户端连接
1
2
3
4
5
6
qemu-system-riscv64 \
-machine virt \
-nographic \
-bios <bootloader地址> \
-device loader,file=<内核镜像地址>,addr=0x80200000 \
-s -S
打开另一个终端,启动一个 GDB 客户端连接到 Qemu :
1
2
3
4
riscv64-unknown-elf-gdb \
-ex 'file <内核镜像地址(无后缀)>' \
-ex 'set arch riscv:rv64' \
-ex 'target remote localhost:1234'
2024.3.13
rust-analyzer补全失效
解决方法:在插件设置中搜索link,在setting中添加所有项目Cargo.toml的绝对路径
1
2
3
4
5
6
7
8
{
"rust-analyzer.linkedProjects": [
"/home/sazikk/workspace/rCore-Tutorial-v3/os/Cargo.toml",
"/home/sazikk/workspace/test_program/backtrace/Cargo.toml",
"/home/sazikk/workspace/test_program/ls/Cargo.toml",
"/home/sazikk/workspace/world_hello/Cargo.toml"
]
}
需要添加在WSL和工作区里
使用Makefile管理项目
实验要求使用makefile管理项目,简化调试流程。注意makefile会识别tab,导致错误。
确实很方便
调用crate::log实现彩色log输出和log等级控制
注意dependency不要加多余的的东西,我加入了env_logger = "0.9"导致严重错误。
基本照着写,明天再仔细读
调用C函数获取内存标志位置
#### 支持多核
完全没有头绪
ch1到这里结束
2024.3.14 第二章 批处理系统
阅读tutorial
2024.3.16
实现用户库和应用程序
在rust项目中,src/main.rs是默认的程序入口,同时rust项目拥有默认的包,名字在Cargo.toml中规定,指向src/lib.rs(如果有lib.rs的话),可以被extern crate直接引用。
添加系统调用
在riscv中,ecall用来触发环境调用,默认a1为第一操作数,a2为第二操作数,a7为系统调用号,返回值存储到a0
- 谁提供了系统调用?
2024.3.19
继续完善应用程序
更新makefile用于在完成系统之前测试应用程序
2024.3.20
开始编写批处理操作系统
cargo build会自动检测并运行项目根目录下的build.rs作为构建脚本。
在子目录下添加mod.rs会把目录变成一个可引用的crate,可以直接 mod。子目录写mod.rs是好文明,能大大简化引用。必须叫mod.rs,又是一个编译器的要求。高手
rust引用库文件方式:
同项目下:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
extern crate crate_name; //整个目录
或
//Cargo.toml
[dependencies]
bin = { path = "src/bin" }
//src/main.rs
use bin::module:item
或
//Cargo.toml
[dependencies]
crate_name = "0.1.0"
//src/main.rs
use crate_name::module:item
或
mod file_name; //必须同目录
use file_name::module:item
或
mod super::filename; //父目录
use filename::module:item
或
pub mod //其他模块中也可以use
不同项目下:
1
2
3
4
5
extern crate crate_name;
或
//Cargo.toml
[dependencies]
crate_name = "0.1.0"
rust的引用真™抽象 屮
2024.3.21
完成batch.rs,阅读代码
rust一般不直接为struct创建成员函数,而是为struct创建实现块(impl),在实现块里实现函数。对于返回Option类型的方法,需要使用.unwrap()方法进行解包,这样可以在出现None时直接panic退出。
rust中有大量概念未理解,如static、内嵌汇编、global_asm等等,并且有大量原生方法不理解,只能靠函数名猜和问gpt。
slice的方法可以获取内存中的一段连续切片,其中可变切片可以用来安全访问一段内存,把应用程序的代码加载到指定位置就由silce实现。
2024.3.22
完成ch2,阅读代码
实现裸机程序,打印调用栈
在项目目录下的.cargo/config里可以设置让编译器对所有函数调用都保存栈指针,创建并修改.cargo/config能对Cargo工具在当前目录下的行为进行调整。
1
2
3
4
5
6
7
8
#world_hello/.cargo/config
[build]
target = "riscv64gc-unknown-none-elf"
[target.riscv64gc-unknown-none-elf]
rustflags = [
"-Clink-arg=-Tsrc/linker.ld","-Cforce-frame-pointers=yes" //强制启用帧指针
]
然后我们就可以从x8/s0/fp寄存器追溯调用栈。
在栈中,栈帧上保存的返回地址和保存的上一个 frame pointer与当前栈帧的相对位置是固定的,如图:
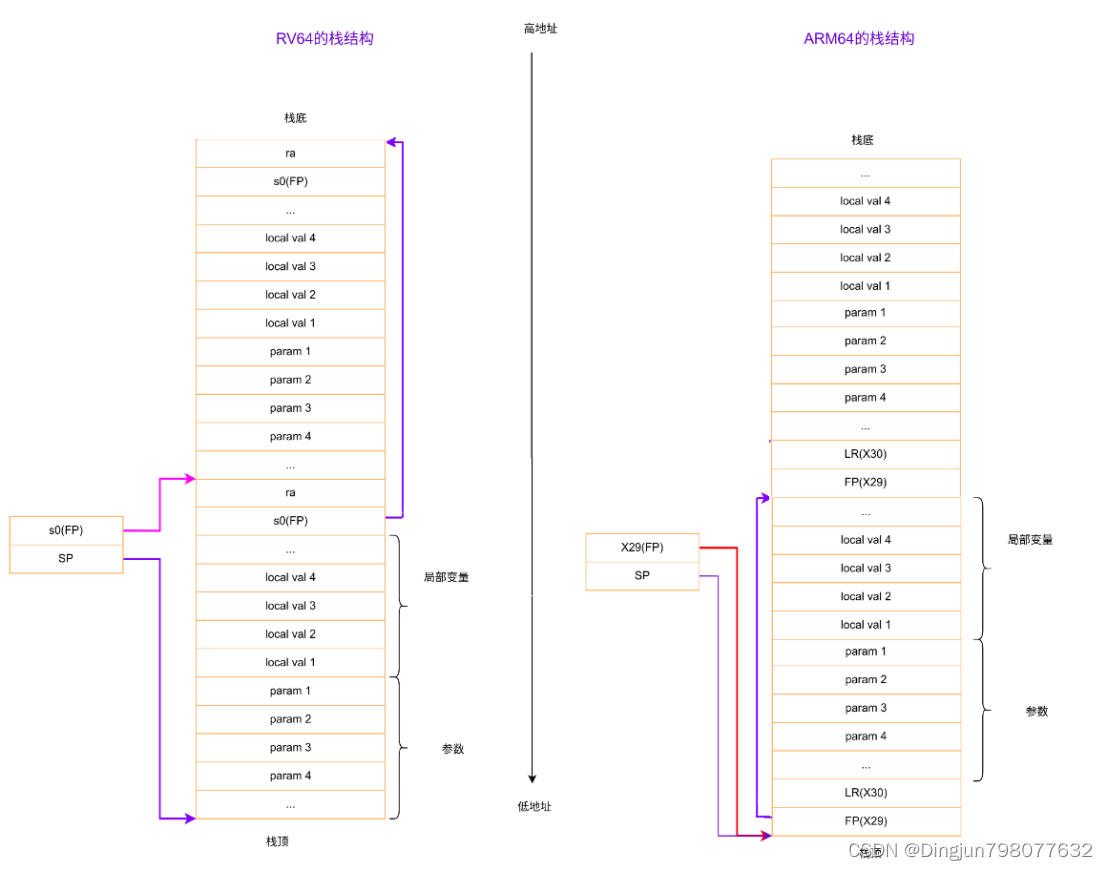
即当前fp的前8个字节为ra,前16个字节位置为上一个frame pointer。所以我们只要获取当前栈帧地址就能回溯之前的返回地址和frame pointer。
1
2
3
4
while frame_pointer != ptr::null() {
let saved_ra = *frame_pointer.sub(1);//指针前移一位8字节的内容
let saved_fp = *frame_pointer.sub(2);
}
最后将完成的打印函数引用到panic函数即可
扩展内核,实现新系统调用get_taskinfo
2,3,4等到ch3再做。
扩展内核,统计执行异常的程序的异常情况(主要是各种特权级涉及的异常),能够打印异常程序的出错的地址和指令等信息
trap_handler已完成大部分工作,只需要加上打印stval内容即可
ch2到此结束
多道程序与分时多任务
ch3代码框架:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
├── bootloader
│ └── rustsbi-qemu.bin
├── LICENSE
├── os
│ ├── build.rs
│ ├── Cargo.toml
│ ├── Makefile
│ └── src
│ ├── batch.rs(移除:功能分别拆分到 loader 和 task 两个子模块)
│ ├── config.rs(新增:保存内核的一些配置)
│ ├── console.rs
│ ├── entry.asm
│ ├── lang_items.rs
│ ├── link_app.S
│ ├── linker-qemu.ld
│ ├── loader.rs(新增:将应用加载到内存并进行管理)
│ ├── main.rs(修改:主函数进行了修改)
│ ├── sbi.rs(修改:引入新的 sbi call set_timer)
│ ├── sync
│ │ ├── mod.rs
│ │ └── up.rs
│ ├── syscall(修改:新增若干 syscall)
│ │ ├── fs.rs
│ │ ├── mod.rs
│ │ └── process.rs
│ ├── task(新增:task 子模块,主要负责任务管理)
│ │ ├── context.rs(引入 Task 上下文 TaskContext)
│ │ ├── mod.rs(全局任务管理器和提供给其他模块的接口)
│ │ ├── switch.rs(将任务切换的汇编代码解释为 Rust 接口 __switch)
│ │ ├── switch.S(任务切换的汇编代码)
│ │ └── task.rs(任务控制块 TaskControlBlock 和任务状态 TaskStatus 的定义)
│ ├── timer.rs(新增:计时器相关)
│ └── trap
│ ├── context.rs
│ ├── mod.rs(修改:时钟中断相应处理)
│ └── trap.S
├── README.md
├── rust-toolchain
└── user
├── build.py(新增:使用 build.py 构建应用使得它们占用的物理地址区间不相交)
├── Cargo.toml
├── Makefile(修改:使用 build.py 构建应用)
└── src
├── bin(修改:换成第三章测例)
│ ├── 00power_3.rs
│ ├── 01power_5.rs
│ ├── 02power_7.rs
│ └── 03sleep.rs
├── console.rs
├── lang_items.rs
├── lib.rs
├── linker.ld
└── syscall.rs
2024.3.24
构建运行ch3-coop,阅读代码
b代码读不动了,开始补一点rust基础
2024.3.25
阅读代码,从汇编层面了解如何处理trap(trap.S)和如何切换任务(换栈,switch.S)
看懂了除了task模块以外所有代码。
0:59拿下task
为应用出错(即trap)实现sys_exit接口
在trap/mod.rs直接调用即可,顺便公开了sys_call id的常量接口
完成阅读“始初龙”代码
实际上已经是3.26凌晨了(
ch3-coop到此结束
2024.3.26
完成ch3代码编写和阅读
https://elixir.bootlin.com可以阅读linux源码
重新封装了一个kernel_msg宏,用于打印内核消息
仿照println,加入了[kernel]前缀并且字体颜色设置为白色(仅针对terminus)
扩展内核,显示任务切换过程
在 mark_current_suspended()函数、mark_current_exited()函数和run_next_task() 函数里设置task状态前添加println就行,打印current task id或next task id
扩展内核,统计每个应用完成时间
首先为TCB添加user_time和kernel_time记录时间
1
2
3
4
5
6
7
#[derive(Copy, Clone)]
pub struct TaskControlBlock {
pub task_status: TaskStatus,
pub task_cx: TaskContext,
pub user_time: usize,
pub kernel_time: usize,
}
然后为TaskManagerInner实现计时方法,使用get_time_ms获取时间,并设置time_cnt控制位,每次更新time_cnt并获取与上一次更新之间的时间间隔来完成计时
1
2
3
4
5
6
7
impl TaskManagerInner {
fn time_count(&mut self) -> usize {
let last_time = self.time_cnt;
self.time_cnt = get_time_ms();
return self.time_cnt - last_time;
}
}
最后为外部调用进行封装,并在taskmanager的方法中和trap处理中进行计时
1
2
3
4
5
6
7
8
9
10
11
12
//impl TaskManager
fn user_time_start(&self) {
let mut inner = self.inner.exclusive_access();
let current = inner.current_task;
inner.tasks[current].kernel_time += inner.time_count();
}
fn user_time_end(&self) {
let mut inner = self.inner.exclusive_access();
let current = inner.current_task;
inner.tasks[current].user_time += inner.time_count();
}
1
2
3
4
5
6
7
pub fn user_time_start(){
TASK_MANAGER.user_time_start();
}
pub fn user_time_end() {
TASK_MANAGER.user_time_end();
}
编写浮点应用程序A,并扩展内核,支持面向浮点数的正常切换和抢占
难点在于需要在trap时记录浮点寄存器组
非常抽象,写了至少两个多小时
首先需要知道处理浮点数指令之前需要设置sstatus的fs段为非零值,以下为手册原文:
The FS, VS, and XS fields use the same status encoding as shown in Table 3.3, with the four possible status values being Off, Initial, Clean, and Dirty.
Status FS and VS Meaning XS Meaning 0 Off off 1 Initial None dirty or clean, some on 2 Clean None dirty, some clean 3 Dirty Some dirty Encoding of FS[1:0], VS[1:0], and XS[1:0] status fields.
If the F extension is implemented, the FS field shall not be read-only zero. If neither the F extension nor S-mode is implemented, then FS is read-only zero. If S-mode is implemented but the F extension is not, FS may optionally be read-only zero.
可以看到fs段如果为0,浮点数指令将被关闭,使用就会报错。(多看手册是好文明)所以我们需要在使用浮点数指令之前手动修改sstatus.fs的值。fs在sstatus的第13,14位,我们可以使用CSRW或CSRS来修改特权寄存器的值:
csrr t2, sscratch
li t0, 0x00003000 #给t0载入一个立即数
csrs sstatus, t0 #把对应位置置1
fsd f0, 34*8(sp)
fsd f1, 35*8(sp)
fsd f2, 36*8(sp)
li t0, 0x00003000
csrs sstatus, t0 #注意在load前也要设置
fld f0, 34*8(sp)
fld f1, 35*8(sp)
fld f2, 36*8(sp)
fld f3, 37*8(sp)
fld f4, 38*8(sp)
以下是指令介绍:
CSRRW(CSR Read and Write)指令:- 用途:用于读取 CSR 的当前值,并将一个新的值写入 CSR。
- 语法:
CSRRW rd, csr, rs - 功能:将 CSR 的当前值读取到目标寄存器
rd中,然后将寄存器rs的值写入 CSR。 - 示例:
csrrw x3, sstatus, x4
CSRRS(CSR Read and Set)指令:- 用途:用于读取 CSR 的当前值,并将 CSR 的某些位设置为 1。
- 语法:
CSRRS rd, csr, rs - 功能:将 CSR 的当前值读取到目标寄存器
rd中,然后将寄存器rs中的位设置为 1,结果写入 CSR。 - 示例:
csrrs x3, sstatus, x4
CSRRC(CSR Read and Clear)指令:- 用途:用于读取 CSR 的当前值,并将 CSR 的某些位清零。
- 语法:
CSRRC rd, csr, rs - 功能:将 CSR 的当前值读取到目标寄存器
rd中,然后将寄存器rs中的位清零,结果写入 CSR。 - 示例:
csrrc x3, sstatus, x4
CSRW(CSR Write)指令:- 用途:用于将一个值直接写入 CSR,而不需要读取 CSR 的当前值。
- 语法:
CSRW csr, rs - 功能:将寄存器
rs的值直接写入 CSR。 - 示例:
csrw sstatus, x3
为了保险起见我存储了全部的32个浮点数寄存器,具体需要存储哪几个有待学习。
虽然这样的代码在rCore/os里可以运行,但是在我自己的os里仍然报错:(rCore也报错但是正常运行)
1
2
3
error: <inline asm>:37:5: instruction requires the following: 'D' (Double-Precision Floating-Point)
fsd f0, 34*8(sp)
^
经过查询资料,这个问题可能来自global_asm!的一个bug或者llvm的bug。在汇编代码的开头加上.attribute arch, "rv64gc"就可以解决这个bug,这个方法来自github/rust下面的一个issue:global_asm! macro causes non-fatal errors to be printed during compilation for some RISC-V extension instructions when targeting the GC extensions#80608。目前完全不清楚原理。
2024.3.27
扩展内核,支持统计任务开销
因为切换任务开销非常小,所以我们先实现一个统计单位为微秒的计时方法,就是对time::read()的重新封装。然后我们对___switch进行二次封装,加入计时方法,并设置两个静态变量用于存储时间,最后我们封装静态变量,在run_next_task中所有应用结束后,调用方法并打印开销
扩展内核,支持在内核态响应中断
sstatus的sie位可以用来屏蔽S级中断,spp位可以分辨中断的来源,我们可以通过这两个特殊位来实现内核态响应中断。首先我们需要重写trap_handler,拆分为user和kernel两个版本,并通过match语句进行匹配。通过对sstatus寄存器的spp位进行判断来确定是U级中断还是S级中断:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
#[no_mangle]
pub fn trap_handler(cx: &mut TrapContext) -> &mut TrapContext {
match sstatus::read().spp() {
sstatus::SPP::Supervisor => kernel_trap_handler(cx),
sstatus::SPP::User => user_trap_handler(cx),
}
}
pub fn user_trap_handler(cx: &mut TrapContext) -> &mut TrapContext {
user_time_end();
let scause = scause::read();
let stval = stval::read();
match scause.cause() {
·······
}
user_time_start();
return cx;
}
pub fn kernel_trap_handler(cx: &mut TrapContext) -> &mut TrapContext {
let scause = scause::read();
let stval = stval::read();
match scause.cause() {
Trap::Interrupt(Interrupt::SupervisorTimer) => {
// 内核中断来自一个时钟中断
kernel_msg!("kernel interrupt: from timer");
// 标记一下触发了中断
mark_kernel_interrupt();
set_next_trigger();
}
Trap::Exception(Exception::StoreFault) | Trap::Exception(Exception::StorePageFault) => {
panic!("[kernel] PageFault in kernel, bad addr = {:#x}, bad instruction = {:#x}, kernel killed it.", stval, cx.sepc);
}
//异常待补充
_ => {
// 其他的内核异常/中断
panic!("unknown kernel exception or interrupt");
}
}
return cx;
}
然后我们简单封装一个静态变量来指示内核中断是否触发过,在main里调用并打印出一些提示语句:
1
2
3
4
5
6
7
8
9
10
11
trap/mod.rs
static mut KERNEL_INTERRUPT_TRIGGERED: bool = false;
pub fn check_kernel_interrupt() -> bool {
unsafe { (addr_of_mut!(KERNEL_INTERRRUPT_TRIGGERED) as *mut bool).read_volatile() }
}
pub fn mark_kernel_interrupt() {
unsafe{
(addr_of_mut!(KERNEL_INTERRRUPT_TRIGGERED) as *mut bool).write_volatile(true);
}
}
这里要注意参考答案的&mut KERNEL_INTERRUPT_TRIGGERED as *mut bool需要写成addr_of_mut!(KERNEL_INTERRRUPT_TRIGGERED) as *mut bool,否则则会报错,rust提示参考答案的写法可能导致未定义行为。
接下来在main里添加一段测试程序:
1
2
3
4
5
6
7
8
9
10
11
12
timer::set_next_trigger();
use riscv::register::sstatus;
unsafe { sstatus::set_sie() }; // 打开内核态中断
loop {
if trap::check_kernel_interrupt() {
println!("kernel interrupt returned.");
break;
}
}
unsafe { sstatus::clear_sie() }; // 关闭内核态中断
task::run_first_task();
- 在函数中不使用
clear_sie / set_sie来开关中断的原因是:RISC-V会自动在中断触发时关闭SIE,sret返回时打开SIE,而若打开中断的时机不恰当可能造成严重bug。
最后我们要对trap.S的代码进行处理,因为这里才是中断的实际入口。主要是需要处理是否换栈的问题:用户中断需要换栈,而内核中断不需要。下面的代码省略了浮点数寄存器。
#trap/trap.S
__alltraps:
csrr tp, sstatus
andi tp, tp, 0x100
beqz tp, __user_trap_start
j __real_trap_entry
__user_trap_start:
csrrw sp, sscratch, sp
__real_trap_entry:
# now sp->kernel stack, sscratch->user stack
# allocate a TrapContext on kernel stack
addi sp, sp, -34*8
......
__restore:
# now sp->kernel stack(after allocated), sscratch->user stack
# restore sstatus/sepc
ld t0, 32*8(sp)
ld t1, 33*8(sp)
ld t2, 2*8(sp)
csrw sstatus, t0
csrw sepc, t1
csrw sscratch, t2
# get SPP
andi t0, t0, 0x100
bnez t0, __kernel_trap_end
__user_trap_end:
# restore general-purpuse registers except sp/tp
ld x1, 1*8(sp)
ld x3, 3*8(sp)
.set n, 5
.rept 27
LOAD_GP %n
.set n, n+1
.endr
# release TrapContext on kernel stack
addi sp, sp, 34*8
# now sp->kernel stack, sscratch->user stack
csrrw sp, sscratch, sp
sret
__kernel_trap_end:
# restore general-purpuse registers except sp/tp
ld x1, 1*8(sp)
ld x3, 3*8(sp)
.set n, 5
.rept 27
LOAD_GP %n
.set n, n+1
.endr
# release TrapContext on kernel stack
addi sp, sp, 34*8
sret
省流:内核trap相比用户trap只是少了两句csrrw sp, sscratch, sp,这通过跳转指令实现。
上面的代码实现中,tp寄存器被征用,这样原本的数据就無了。为了避免这个问题,我们使用一个小技巧:在实际的内核中,用户空间往往在低地址(0x00000......),而内核空间在高地址(0xfffff......),所以直接判断sp的符号就能判断是在哪个栈发生的中断。
__alltraps:
bgtz sp, __user_trap_start
j __real_trap_entry
__user_trap_start:
csrrw sp, sscratch, sp
__real_trap_entry:
# now sp->kernel stack, sscratch->user stack
# allocate a TrapContext on kernel stack
addi sp, sp, -34*8
......
ch3问答题整理:
- 如何判断进入操作系统内核的起因是由于中断还是异常?
检查 mcause 寄存器的最高位,1 表示中断,0 表示异常。
当然在 Rust 中也可以直接利用 riscv 库提供的接口判断:
1
2
3
4
5
6
7
let scause = scause::read();
if scause.is_interrupt() {
do_something
}
if scause.is_exception() {
do_something
}
又或者,可以按照 trap/mod.rs:trap_handler() 中的写法,用 match scause.cause() 来判断。
在 RISC-V 中断机制中,PLIC 和 CLINT 各起到了什么作用?
CLINT 处理时钟中断 (
MTI) 和核间的软件中断 (MSI);PLIC 处理外部来源的中断 (MEI)。PLIC 的规范文档: https://github.com/riscv/riscv-plic-spec
基于RISC-V 的操作系统支持中断嵌套?请给出进一步的解释说明。
RISC-V原生不支持中断嵌套。(在S态的内核中)只有 sstatus 的 SIE 位为 1 时,才会开启中断,再由 sie 寄存器控制哪些中断可以触发。触发中断时,sstatus.SPIE 置为 sstatus.SIE,而 sstatus.SIE 置为0;当执行 sret 时,sstatus.SIE置为 sstatus.SPIE,而 sstatus.SPIE 置为1。这意味着触发中断时,因为 sstatus.SIE 为0,所以无法再次触发中断。
- 简单描述一下任务的地址空间中有哪些类型的数据和代码。
可参照 user/src/linker.ld:
.text:任务的代码段,其中开头的.text.entry段包含任务的入口地址.rodata:只读数据,包含字符串常量,如测例中的println!("Test power_3 OK!");实际打印的字符串存在这里.data:需要初始化的全局变量.bss:未初始化或初始为0的全局变量。- 在之后第四章的
user/src/bin/00power_3.rs中,会把第三章中在用户栈上定义的数组移到全局变量中static mut S: [u64; LEN] = [0u64; LEN]; - 在第五章的
user/lib.rs中,会在bss段构造一个用户堆static mut HEAP_SPACE: [u8; USER_HEAP_SIZE] = [0; USER_HEAP_SIZE];
- 在之后第四章的
除此之外,在内核中为每个任务构造的用户栈 os/src/loader.rs:USER_STACK也属于各自任务的地址。
任务上下文切换需要保存与恢复哪些内容?
需要保存通用寄存器的值,PC;恢复的时候除了保存的内容以外还要恢复特权级到用户态。
ch3到此结束
地址空间
2024.3.30-4.1
阅读ch4代码。
ch4用到了rust的drop trait,rust在每个变量离开作用域时会自动调用drop方法,你可以自己实现drop,添加对变量对应资源的释放,这样就无需手动释放每一个资源。
内核栈和用户栈:
内核栈(Kernel Stack): 内核栈是操作系统内核为每个运行的进程或线程分配的栈空间。它用于存储内核级别的函数调用、中断处理、异常处理以及其他与内核执行相关的操作。每个进程或线程都有自己的内核栈,它在进程或线程创建时被分配,并在进程或线程切换时被切换。
内核栈通常位于内核地址空间的顶部或底部,具体取决于操作系统的设计。它的大小是固定的,并且在编译或运行时被定义。内核栈的大小通常比用户栈大,以便处理内核级别的函数调用和中断处理时所需的额外空间。
用户栈(User Stack): 用户栈是用于存储用户级别的函数调用、局部变量和函数参数的栈空间。它是每个进程的一部分,用于处理用户程序的执行。用户栈通常位于用户程序的地址空间的顶部,与内核栈分开。
用户栈的大小在进程创建时被定义,并且可以根据需要动态增长或缩小。用户栈的大小通常比内核栈小,因为它主要用于用户级别的函数调用和处理用户程序的执行。
保护页,在两个内核栈之间,表现为一段没有映射到虚拟内存的空间,访问就触发异常。
引入分页机制造成的trap改变:
当 __alltraps 保存 Trap 上下文的时候,我们必须通过修改 satp 从应用地址空间切换到内核地址空间,因为 trap handler 只有在内核地址空间中才能访问;同理,在 __restore 恢复 Trap 上下文的时候,我们也必须从内核地址空间切换回应用地址空间,因为应用的代码和数据只能在它自己的地址空间中才能访问,应用是看不到内核地址空间的。这样就要求地址空间的切换不能影响指令的连续执行,即要求应用和内核地址空间在切换地址空间指令附近是平滑的。
2024.4.2
修改内核态中断响应
由于加入地址空间的修改,暂时改为不支持响应内核态的中断,仍然保留了对浮点数的支持。
.attribute arch, “rv64gc”
2024.4.4
拉了兄弟们,还在读ch4
最高虚拟页面:
最高地址取决于系统位数,在64位系统中就是2^64^-1,所以最高页面的位置就是2^64^-1-PAGE_SIZE
2024.4.5
内核代码映射方式:
内核的四个逻辑段 .text/.rodata/.data/.bss 被恒等映射到物理内存,这使得我们在无需调整内核内存布局 os/src/linker.ld 的情况下就仍能象启用页表机制之前那样访问内核的各个段。
2024.4.7
trap处理更新
trap的入口函数的符号为实际物理地址,引入内存管理后,系统内核想要处理trap就需要知道trap入口所映射的虚拟地址。这里就体现了跳板的作用,我们通过链接脚本把存放了trap入口代码的代码段放在符号 strampoline处,把最高虚拟页面的地址设置为跳板地址,再手动将这个地址映射到strampoline,这样即实现了对于内核地址空间和应用地址空间,跳板都位于虚拟地址空间最高处,并且可以通过跳板访问这段处理代码,这样即使地址空间切换,指令控制流仍然正常执行。
gdb使用问题
在lab4之前,对内存访问没有什么限制,但是在lab4启动虚拟内存之后,无法越权访问内存 应该是断点处的内存地址不可访问导致的,使用delete+断点编号删除断点即可 切换到用户程序后,使用 file ../user/target/riscv64gc-unknown-none-elf/debug/00power_3 加载用户程序调试信息,使用b syscall设置用户态断点 切换系统用户/内核状态之前需要清除断点 待切换回内核态时,再使用 file target/riscv64gc-unknown-none-elf/debug/os 重新加载内核调试信息,使用b *0xfffffffffffff000等设置内核断点
以上方法可以调试ecall/sret这样手动切换状态,但是对时钟这样的自动中断好像还不好调试
ch4结束,练习题暂时翘了
2024.4.8 - 4.12
摆了,写两天rustlings
5天才写完,拉了